Forschung rund um künstliche Intelligenz

Auf dieser Seite möchte ich euch ein paar meiner Forschungsarbeiten präsentieren. Da die Sprache der Forschung englisch ist, sind meine Papers ebenfalls auf englisch. Nach und nach werde ich die Schlüsselideen übersetzen, damit ihr euch einen schnellen Überblick verschaffen könnt. Bis dahin poste ich hier einfach mal die englischen Zusammenfassungen der Artikel und die Links zu den Papers. Viel Spaß beim Lesen 🙂
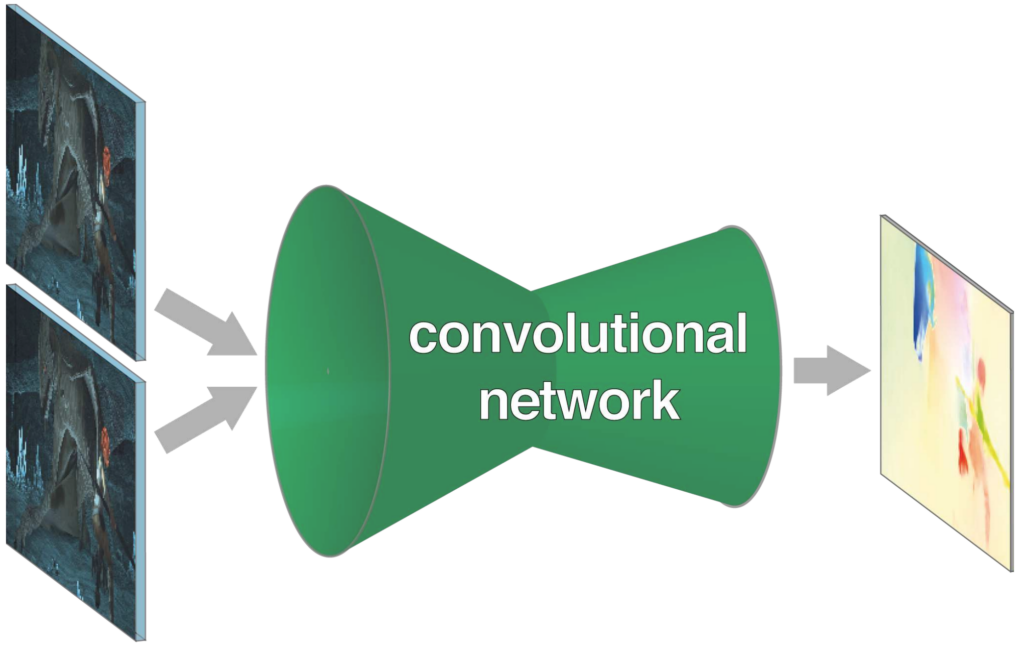
Flownet: Learning optical flow with convolutional networks
International Conference on Computer Vision (ICCV) 2015
Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Haeusser, Caner Hazirbas, Vladimir Golkov, Patrick Van Der Smagt, Daniel Cremers, Thomas BroxConvolutional neural networks (CNNs) have recently been very successful in a variety of computer vision tasks, especially on those linked to recognition. Optical flow estimation has not been among the tasks CNNs succeeded at. In this paper we construct CNNs which are capable of solving the optical flow estimation problem as a supervised learning task. We propose and compare two architectures: a generic architecture and another one including a layer that correlates feature vectors at different image locations. Since existing ground truth data sets are not sufficiently large to train a CNN, we generate a large synthetic Flying Chairs dataset. We show that networks trained on this unrealistic data still generalize very well to existing datasets such as Sintel and KITTI, achieving competitive accuracy at frame rates of 5 to 10 fps.
A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016
Nikolaus Mayer, Eddy Ilg, Philip Haeusser, Philipp Fischer, Daniel Cremers, Alexey Dosovitskiy, Thomas BroxRecent work has shown that optical flow estimation can be formulated as a supervised learning task and can be successfully solved with convolutional networks. Training of the so-called FlowNet was enabled by a large synthetically generated dataset. The present paper extends the concept of optical flow estimation via convolutional networks to disparity and scene flow estimation. To this end, we propose three synthetic stereo video datasets with sufficient realism, variation, and size to successfully train large networks. Our datasets are the first large-scale datasets to enable training and evaluation of scene flow methods. Besides the datasets, we present a convolutional network for real-time disparity estimation that provides state-of-the-art results. By combining a flow and disparity estimation network and training it jointly, we demonstrate the first scene flow estimation with a convolutional network.

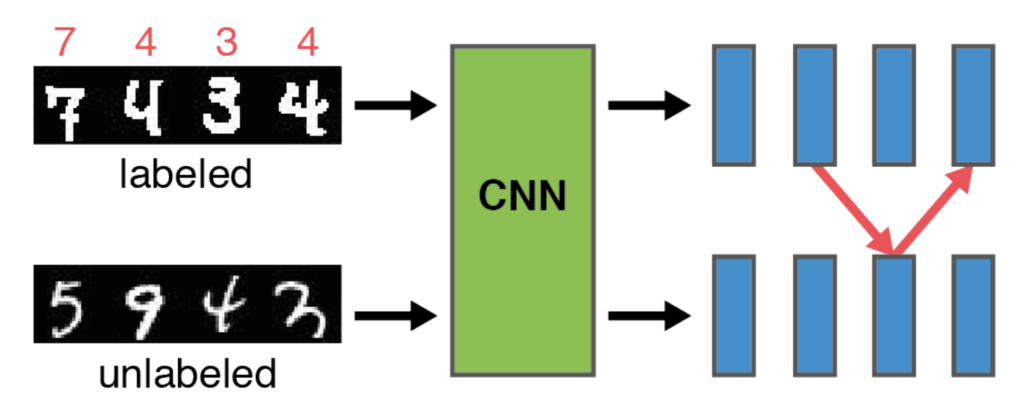
Learning by Association – A versatile semi-supervised training method for neural networks
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017
Philip Haeusser, Alexander Mordvintsev, Daniel CremersIn many real-world scenarios, labeled data for a specific machine learning task is costly to obtain. Semi-supervised training methods make use of abundantly available unlabeled data and a smaller number of labeled examples. We propose a new framework for semi-supervised training of deep neural networks inspired by learning in humans.“ Associations“ are made from embeddings of labeled samples to those of unlabeled ones and back. The optimization schedule encourages correct association cycles that end up at the same class from which the association was started and penalizes wrong associations ending at a different class. The implementation is easy to use and can be added to any existing end-to-end training setup. We demonstrate the capabilities of learning by association on several data sets and show that it can improve performance on classification tasks tremendously by making use of additionally available unlabeled data. In particular, for cases with few labeled data, our training scheme outperforms the current state of the art on SVHN.
Better text understanding through image-to-text transfer
arXiv 2017
Karol Kurach, Sylvain Gelly, Michal Jastrzebski, Philip Haeusser, Olivier Teytaud, Damien Vincent, Olivier BousquetGeneric text embeddings are successfully used in a variety of tasks. However, they are often learnt by capturing the co-occurrence structure from pure text corpora, resulting in limitations of their ability to generalize. In this paper, we explore models that incorporate visual information into the text representation. Based on comprehensive ablation studies, we propose a conceptually simple, yet well performing architecture. It outperforms previous multimodal approaches on a set of well established benchmarks. We also improve the state-of-the-art results for image-related text datasets, using orders of magnitude less data.
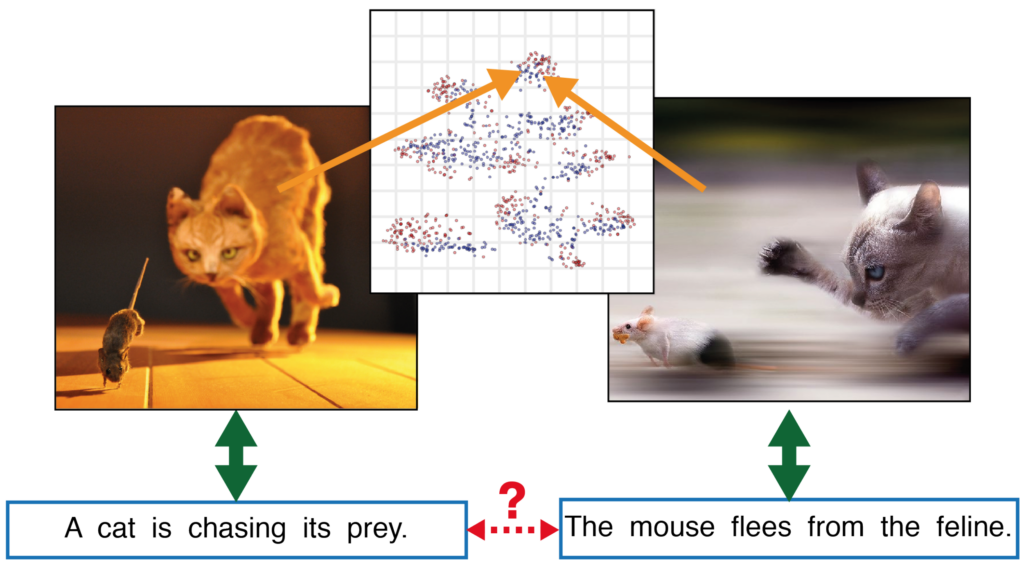
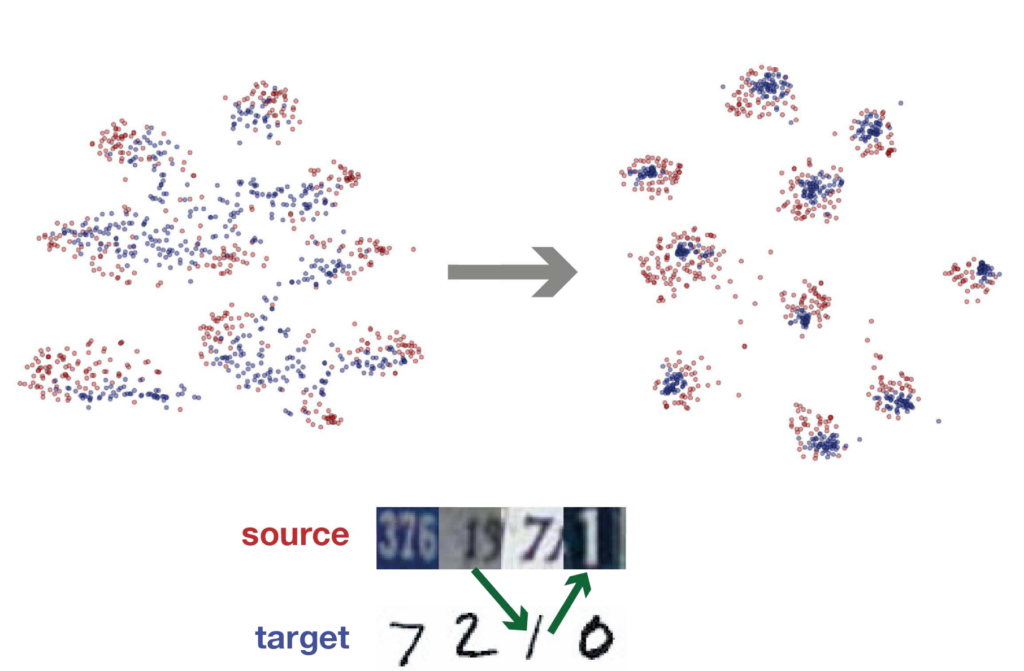
Associative Domain Adaptation
International Conference on Computer Vision (ICCV) 2017
Philip Haeusser, Thomas Frerix, Alexander Mordvintsev, Daniel CremersWe propose“ associative domain adaptation“, a novel technique for end-to-end domain adaptation with neural networks, the task of inferring class labels for an unlabeled target domain based on the statistical properties of a labeled source domain. Our training scheme follows the paradigm that in order to effectively derive class labels for the target domain, a network should produce statistically domain invariant embeddings, while minimizing the classification error on the labeled source domain. We accomplish this by reinforcing“ associations“ between source and target data directly in embedding space. Our method can easily be added to any existing classification network with no structural and almost no computational overhead. We demonstrate the effectiveness of our approach on various benchmarks and achieve state-of-the-art results across the board with a generic convolutional neural network architecture not specifically tuned to the respective tasks. Finally, we show that the proposed association loss produces embeddings that are more effective for domain adaptation compared to methods employing maximum mean discrepancy as a similarity measure in embedding space.
Associative Deep Clustering: Training a Classification Network with no Labels
German Conference on Pattern Recognition (GCPR) 2018
Philip Haeusser, Johannes Plapp, Vladimir Golkov, Elie Aljalbout, Daniel CremersWe propose a novel end-to-end clustering training schedule for neural networks that is direct, i.e. the output is a probability distribution over cluster memberships. A neural network maps images to embeddings. We introduce centroid variables that have the same shape as image embeddings. These variables are jointly optimized with the network’s parameters. This is achieved by a cost function that associates the centroid variables with embeddings of input images. Finally, an additional layer maps embeddings to logits, allowing for the direct estimation of the respective cluster membership. Unlike other methods, this does not require any additional classifier to be trained on the embeddings in a separate step. The proposed approach achieves state-of-the-art results in unsupervised classification and we provide an extensive ablation study to demonstrate its capabilities.
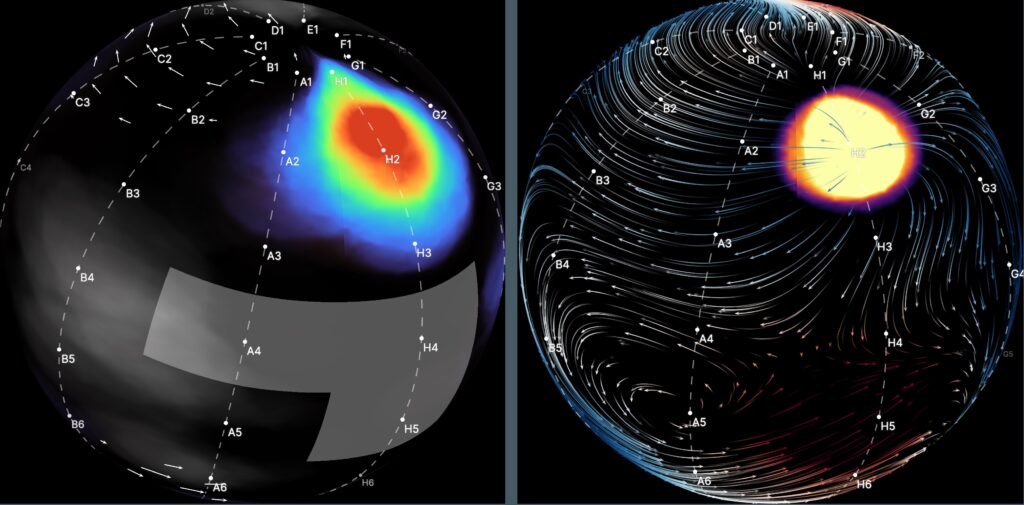
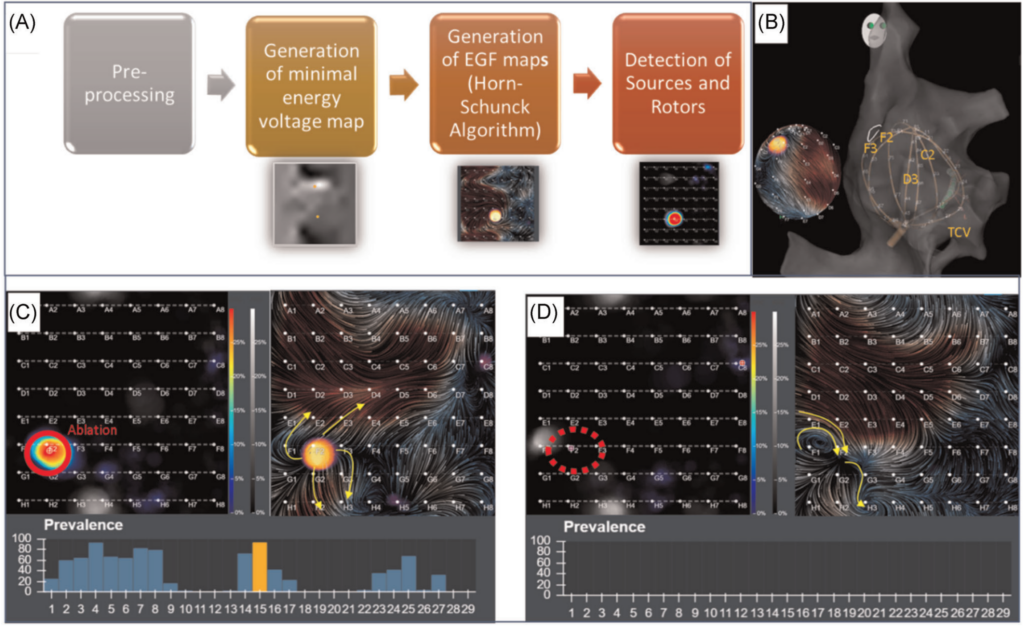
Systems, Devices, Components and Methods for Detecting the Locations of Sources of Cardiac Rhythm Disorders in a Patient’s Heart
U.S. Patent 2020
Philip Haeusser, Peter RuppersbergDisclosed are various examples and embodiments of systems, devices, components and methods configured to detect a location of a source of at least one cardiac rhythm disorder in a patient’s heart. In some embodiments, electrogram signals are acquired from a patient’s body surface, and subsequently normalized, adjusted and/or filtered, followed by generating a two-dimensional spatial map, grid or representation of the electrode positions, processing the amplitude-adjusted and filtered electrogram signals to generate a plurality of three-dimensional electrogram surfaces corresponding at least partially to the 2D map, one surface being generated for each or selected discrete times, and processing the plurality of three-dimensional electrogram surfaces through time to generate a velocity vector or other type of map using one or more of optical flow, video tracking analysis, motion capture analysis, motion …
Functional Electrographic Flow Patterns in Patients with Persistent Atrial Fibrillation Predict Outcome of Catheter Ablation
Journal of Cardiovascular Electrophysiology 2021
Tamas Szili‐Torok, Zsuzsanna Kis, Rohit Bhagwandien, Sip Wijchers, Sing‐Chien Yap, Mark Hoogendijk, Nadege Dumas, Philip Haeusser, Tamas Geczy, MD Melissa Kong, Peter RuppersbergAims: Electrographic flow (EGF) mapping is a method to detect action potential sources within the atria. In a double‐blinded retrospective study we evaluated whether sources detected by EGF are related to procedural outcome.
Methods: EGF maps were retrospectively generated using the Ablamap® software from unipolar data recorded with a 64‐pole basket catheter from patients who previously underwent FIRM‐guided ablation. We analyzed patient outcomes based on source activity (SAC) and Variability. Freedom from AF was defined as no recurrence of AF, atypical flutter or atrial tachycardia at the follow‐up visits.
Results: EGF maps were from 123 atria in 64 patients with persistent or long‐standing persistent AF. Procedural outcome correlation with source activity peaked at > 26%. S‐Type EGF signature (source‐dependent AF) is characterized by stable sources with SAC > 26% and C‐Type (source …